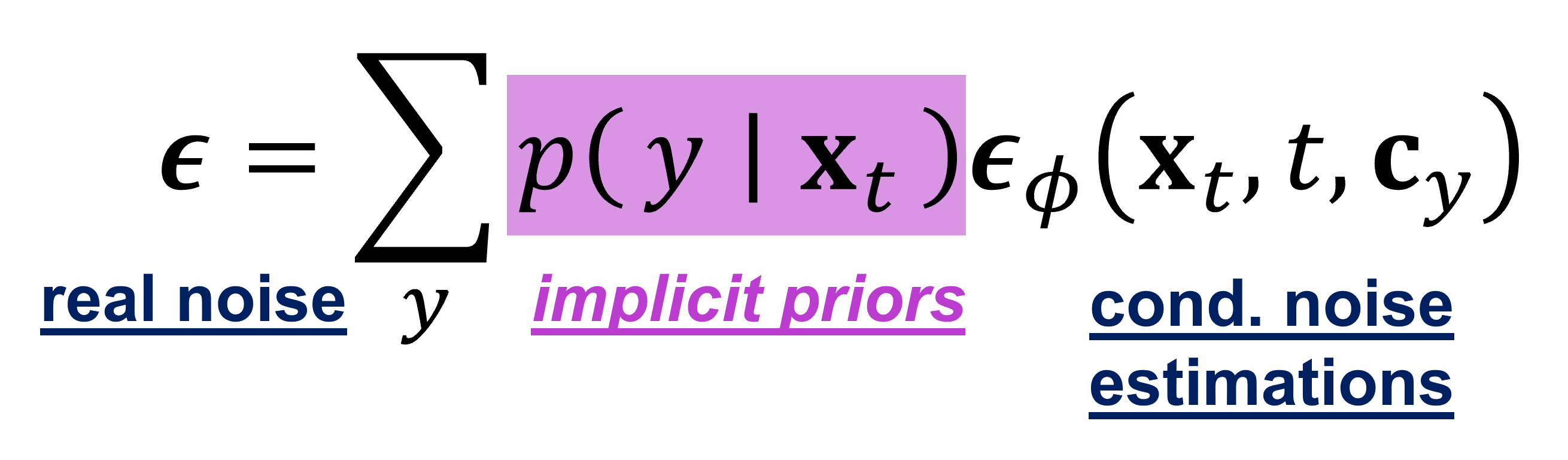
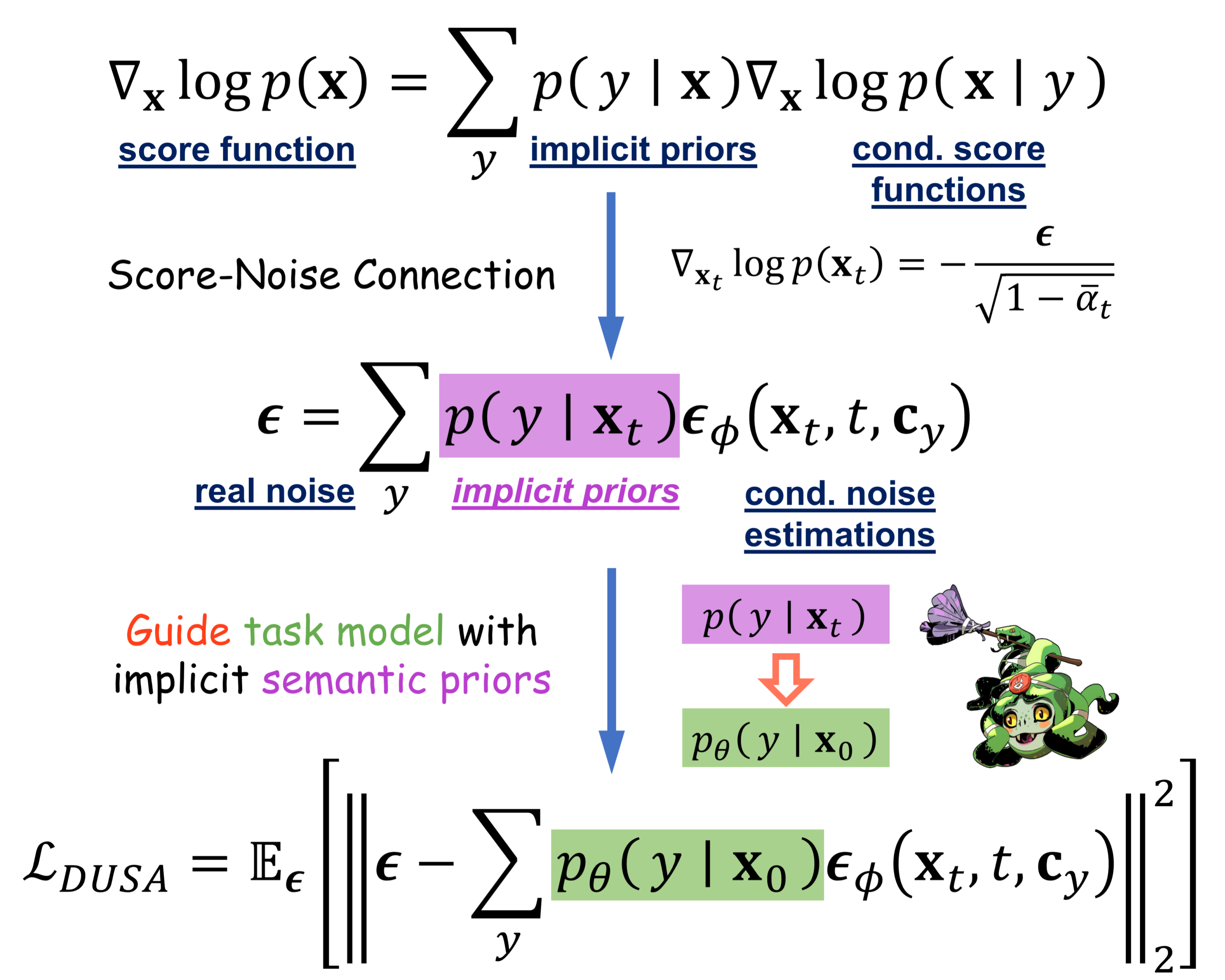
- The task model drains knowledge from the structured semantic priors underlying the diffusion model
- Both models are jointly updated with our DUSA objective
- A Candidate Selection Module (CSM) is proposed to improve adaptation efficiency
title={Exploring Structured Semantic Priors Underlying Diffusion Score for Test-time Adaptation},
author={Mingjia Li and Shuang Li and Tongrui Su and Longhui Yuan and Jian Liang and Wei Li},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=c7m1HahBNf}
}